Caption Generation
One project I worked on during my last quarter at Stanford was an unambiguous caption generator. This was a final project for CS224n: Natural Language Processing with Deep Learning. The task we chose was to generate a caption that describes a target image, but not a distractor image.
As an example, let's say we were given an image of a small, brown dog running through a field as the target and an image of a small, brown dog sitting on a couch as the distractor. An ambiguous caption would read "a small, brown dog," as that could describe either image. Our goal was to generate an unambiguous caption, such as "a dog running through a field," which describes only the target image.
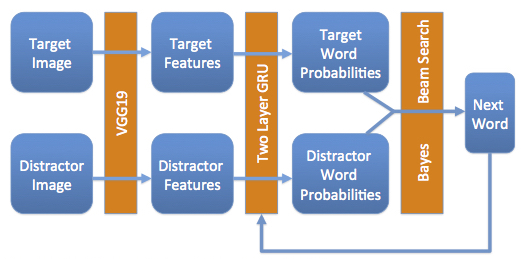
The diagram above shows our model and you can read more about Google's work on this. This project was particularly rewarding since it combined several areas of interest for me: image processing, language processing, deep learning, and working with very large datasets. Though we didn't have time to run every experiment we wanted to, this was easily one of the most engaging and challenging projects I've been a part of.
